C++ pode ter a fama de ser uma linguagem com complexidade comparável à legislação tributária brasileira, mas ao mesmo tempo é uma linguagem extremamente poderosa, podendo ser usada tanto desde microcontroladores até super computadores, sem contar satélites espaciais. Tamanha complexidade pode assustar quem vem de linguagens mais simples como Python (malloc? rvalue references?). Uma ajuda para tratar essa sensação de “como que eu faço aquilo?” pode ser conhecer as ferramentas que a linguagem oferece em comparação com o que já estamos acostumados.
Nessa série de posts vamos mostrar uma visão geral de algumas dessas ferramentas de C++ e comparar como seria a funcionalidade equivalente em Python. Mais especificamente, a STL – Standard Template Library – e seu header <algorithm>. Esse header possui várias funções que podem simplificar o código e deixar o programador que vem de Python mais à vontade, sem ter que fazer tanta coisa “na mão”. Mas antes de entrar na STL propriamente dita, é importante conhecer o que são os templates de C++, que são o bloco fundamental da STL.
Antes de tudo, um aviso: Dadas as diferenças das linguagens, certamente existirão formas mais eficientes de aplicar alguns conceitos de C++ do que uma mera conversão 1-1 de código em Python, especialmente no que diz respeito ao gerenciamento de recursos (RAII vs gc vs mallocs, etc). Longe de ser um tratado de como extrair o máximo de C++, o objetivo destes posts é apenas facilitar um pouco a vida dos expatriados.
Templates
Templates são uma ferramenta muito útil para programação genérica, permitindo reuso de código de uma maneira mais segura. Numa analogia bem grosseira, eles podem ser vistos como uma espécie de “duck typing em tempo de compilação” de C++. Duck typing no sentido de que, diferente de uma função ou classe normal onde o desenvolvedor já escreve explicitamente quais são todos os tipos envolvidos, num template alguns tipos podem ficar em aberto, para serem definidos posteriormente. O usuário do template então escreve seu código usando ele normalmente e o compilador cuida de checar se todos os tipos fornecidos para o template implementam as operações necessárias para ele ser gerado.
Por exemplo, a função add abaixo recebe como parâmetro do template um tipo T, os dois parâmetros da função são do tipo T e o retorno também é do tipo T. Dentro, é chamado o operador +() para os dois parâmetros T. Como o exemplo mostra, ela pode ser usada tanto para inteiros como para strings:
#include <iostream> // Para imprimir na tela
template <class T>
T add(T a, T b)
{
return a + b; // operator +()
}
int main()
{
int x = 5;
int y = 4;
std::string name = "Monty";
std::string surname = "Python";
std::cout << add(x, y) << std::endl;
std::cout << add(name, surname) << std::endl;
return 0;
}
Templates são o cerne da STL, usados por exemplo, nos containers, para definir o tipo a ser guardado nas coleções (std::vector<T>, std::map<K, V>). Além disso, também são usados em coisas mais esotéricas de C++ como Template Metaprogramming, onde as features de template são usadas para efetivamente rodar programas dentro do compilador e estão muito além do escopo dessa série.
Uma diferença entre os templates C++ e as funções normais de Python está no código gerado. Em python, você normalmente só tem uma única instância da função e a máquina virtual faz o “duck typing” em tempo de execução, chamando os métodos dos tipos apropriados. Mas como o código em C++ é convertido diretamente em código executável, sem um interpretador ou máquina virtual, o compilador na prática efetua a substituição dos tipos nos templates e gera uma função “anônima” para aquela substituição (conjunto de tipos). Isso é a chamada instanciação de templates. Ou seja, um eventual template add<T>(T a, T b) que seja chamado para T = int e T = std::string vai gerar duas funções, algo como __add_int(int a, int b) e __add_string(std::string a, std::string b). Por isso que algums sistemas que abusam demais de templates podem acabar ficando grandes demais se não tivermos cuidado.
STL: A Biblioteca Padrão de Arcabouços Templates
A STL é um dos pilares do C++ moderno. E ela pode ser dividida em 4 principais componentes: Containers, Iteradores, Funções e Algoritmos.
Os containers são classes que armazenam elementos, cuidando do gerenciamento de memória usado para guardar os mesmos e oferecendo uma interface uniforme de acesso através de iteradores. Entre os containers oferecidos estão listas (std::list), mapas (std::map), filas de prioridade (std::priority_queue) e outros. Os containers são implementados como templates para facilitar o reuso deles para diferentes tipos de objetos a serem armazenados.
Iteradores (descritos em maior profundidade mais abaixo) são formas de acessar os items de um container de maneira uniforme, sem se preocupar tanto com o container específico. Por exemplo, ao iterar uma sequencia de itens, você pode acessar da mesma maneira tanto uma std::list quanto um std::vector. Numa analogia com Python, os containers seriam iterables e os iterators seria, bem, iterators.
Funções são representadas principalmente pelos function objects, classes que fazem overload do operator (), semelhante ao método __call__(). Isso permite por exemplo você fornecer predicados para as funções de algoritmo de maneira mais simples. Um functor pode armazenar um contexto mais apropriado para um determinado predicado do que um mero ponteiro de função ou um lambda. Alguns dos tipos de funções mais utilizados pela STL são os Predicate (funções unárias retornando booleano sem modificar o argumento) e os BinaryPredicate (funções binárias retornando booleano sem modificar o argumento). Imagine std::function (a principal classe function object) como sendo poder passar funções C++ como um objeto qualquer, como em Python.
Algoritmos por sua vez fazem uso extensivo desses containers, iteradores e funções para implementar diversas funcionalidades, como map, reduce, produto interno, merge, heap, etc.
Iteradores
Na prática, iteradores são uma ferramenta que permite acessar o conteúdo de containers como mapas, listas, vetores, strings sem se importar diretamente com a estrutura de dados por baixo. Um iterador pode ser visto como um ponteiro que num dado momento referencia algum item do container. A semelhança é tanta com ponteiros que o operator * é usado para acessar o conteúdo de um iterator, tal qual ponteiros.
Os iterators se agrupam em de acordo com suas funcionalidades, por exemplo, se permitem só leitura (Input iterators), se os dados podem ser acessados randomicamente (Random Access iterators) ou sequencialmente (Forward / Bidirectional iterators), se permite modificação ou não (const vs non-const iterators), etc.
Normalmente, os dois métodos mais utilizadas para acessar os iterators de um container são begin() e end(). O primeiro retorna um iterador para o primeiro elemento do container, enquanto a segunda retorna uma posição além do final do container (ambas formando o intervalo [begin, end), assim como o range() de Python).
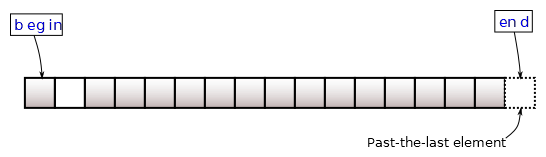
(Fonte da imagem: Método begin())
Um dos usos mais comuns de iteradores em C++ é nos for loops. Tradicionalmente, os loops em C/C++ com iteradores possuem a forma:
for (auto it = cont.begin(); it != cont.end(); it++) {...}
Com C++11, os range loops permitem usar uma sintaxe mais enxuta (e parecida com o for…in de Python):
for (auto&& it : cont) {...}
Na prática, é apenas um açúcar sintático para primeira forma, onde o compilador automaticamente declara, compara e incrementa as variáveis. Se cont for uma classe que possui os métodos begin() e end() – como vários containers – eles serão utilizados para inicializar e comparar os iteradores.
No próximo post, começaremos a destrinchar o <algorithm> comparando com as funções análogas de Python.
o/

